DB: 集計 count、max、min、avg、sum
$query = ¥DB::table('nekos');
dump($query->toSql()); // "select * from `nekos`"
$value1 = $query->count('id'); // 件数
$value2 = $query->max('neko_val'); // 最大
$value3 = $query->min('neko_val'); // 最小
$value4 = $query->avg('neko_val'); // 平均
$value5 = $query->sum('neko_val'); // 合計
DB: 大型データの分割処理 チャンク
数万件ものデータをDBから取得しようとするとメモリーオーバーのエラーが発生する場合がある。 このエラーを回避する仕組みとしてチャンクという技術がある。 チャンクとは大きな塊という意味。例えば10万件のデータを処理する場合、 一度に10万件をDBから取得するのでなく、1000件ずつの塊(チャンク)を少しずつ取得して処理を行うなら、 メモリーオーバーエラーを回避できる。
下記の例は4件ずつデータを取得し、その4件のデータをループしつつなんらかの処理を行っている。
¥DB::table('nekos')->orderBy('id')->chunk(4, function ($chunk) {
dump(count($chunk));// → 4 → 4件ずつDBからデータ取得していることを意味している。
foreach ($chunk as $ent) {
$ent = (array)$ent;
// ~ なんらかの処理
}
});

DB: レコードの存在チェック
$res = ¥DB::table('nekos')->where('id', 4)->exists(); // true:レコード存在, false:存在しない
DB: LIMITとOFFSET
$query = ¥DB::table('nekos')
->offset(10)
->limit(5);
dump($query->toSql()); // → "select * from `nekos` limit 5 offset 10"
$data = $query->get();
dump($data);
DB: ORDER BY句 | orderBy
$query = ¥DB::table('nekos')->orderBy('neko_name');
dump($query->toSql()); // → "select * from `nekos` order by `neko_name` asc"
$data = $query->get();
dump($data);
DESC
$query = ¥DB::table('nekos')->orderBy('neko_name', 'desc');
dump($query->toSql()); // →"select * from `nekos` order by `neko_name` desc"
$data = $query->get();
dump($data);
DB: WHEREの直接記述 | whereRaw
$query = ¥DB::table('nekos')->
whereRaw('neko_val = 4')->
orderByRaw('neko_name desc');
dump($query->toSql()); // →"select * from `nekos` where neko_val = 4 order by neko_name desc"
$data = $query->get();
dump($data);
DB: SELECT句
$query = ¥DB::table('nekos')->
select('id', 'neko_name as cat', 'neko_val', 'neko_date');
dump($query->toSql()); // →"select `id`, `neko_name` as `cat`, `neko_val`, `neko_date` from `nekos`"
$data = $query->get();
dump($data);
DB: SELECTの直接記述 | selectRaw
$query = ¥DB::table('nekos')->
selectRaw('id, neko_name, neko_val as CatValue');
dump($query->toSql()); // →"select id, neko_name, neko_val as CatValue from `nekos`"
$data = $query->get();
dump($data);
セッションをDBに保存する設定 | session
-
プロジェクトのルートディレクトリの直下に存在する「.env」を開き、下記のように書き換える
SESSION_DRIVER=database
-
config/session.phpを開き、下記のように修正
'driver' => env('SESSION_DRIVER', 'database') -
ターミナルやGit BashなどでコマンドUIを起動し、cdコマンドでプロジェクトのルートディレクトリへ移動
cd ルートディレクトリへのパス
-
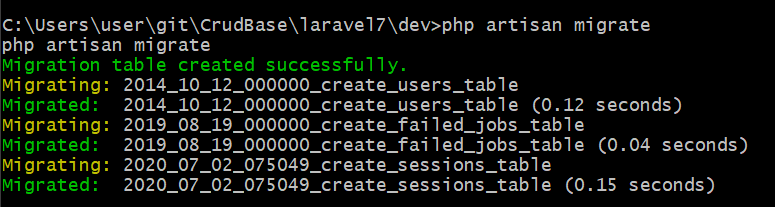
下記のコマンドを実行すると、sessionテーブルのマイグレーションファイルが「database/migrations」ディレクトリに作成される。
php artisan session:table

-
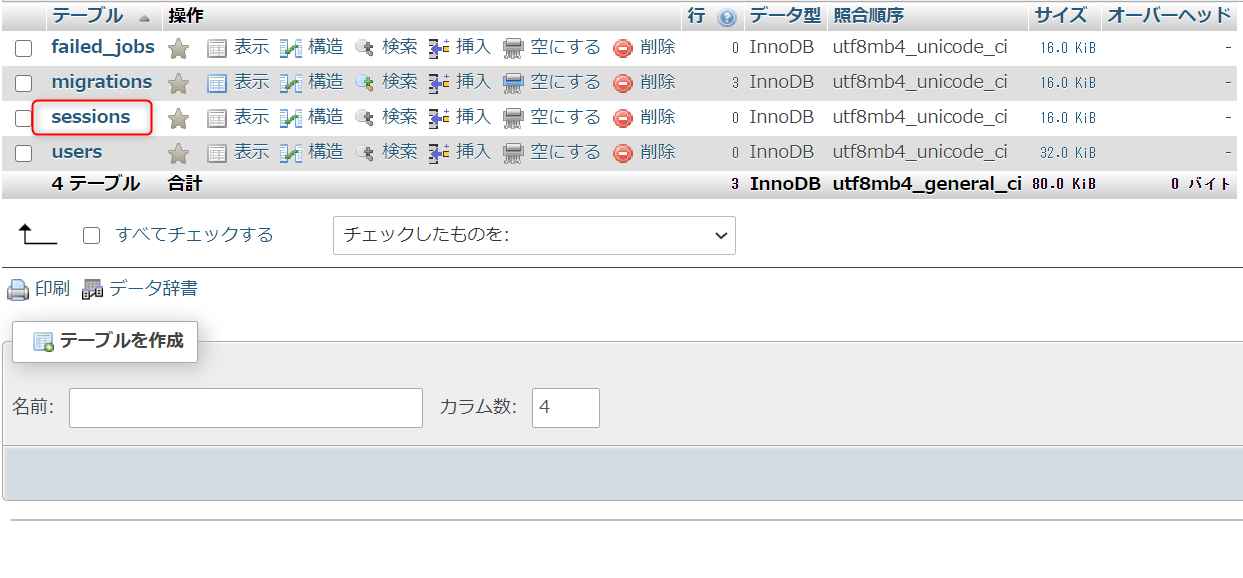
下記のコマンドを実行すると、関連づけているDBにsessionsテーブルが作成される。
php artisan migrate
phpMyAdmin
- 以上で設定終わり
セッションへの書き込み、または読み取り | session
セッションへ書き込み
¥Session::put('neko_key', '赤猫');
// 配列も指定可能
¥Session::put('dog_key', ['dog_name'=>'白犬', 'age'=>10]);
セッションから読み取り
$value = session('neko_key');
「'App\Http\Controllers\Session' not found」エラーが起きる場合、下記の宣言を行う。
use Illuminate\Http\Request;
use Illuminate\Support\Facades\Session;
注意事項
- セッションへの書き込みに 「session('neko_key', '赤猫');」という記述方法が紹介されているが、同一リクエスト内でのみでしか有効でない。なので避けるべき。
- ソースコードを修正して変更するとセッションの保存データがリセットされることがある。